linux性能优化实战学习笔记——CPU篇
说明
这篇博客用于记录学习linux性能优化实战专栏CPU篇的一些总结,巩固自己知识点的同时也能够方便以后查询
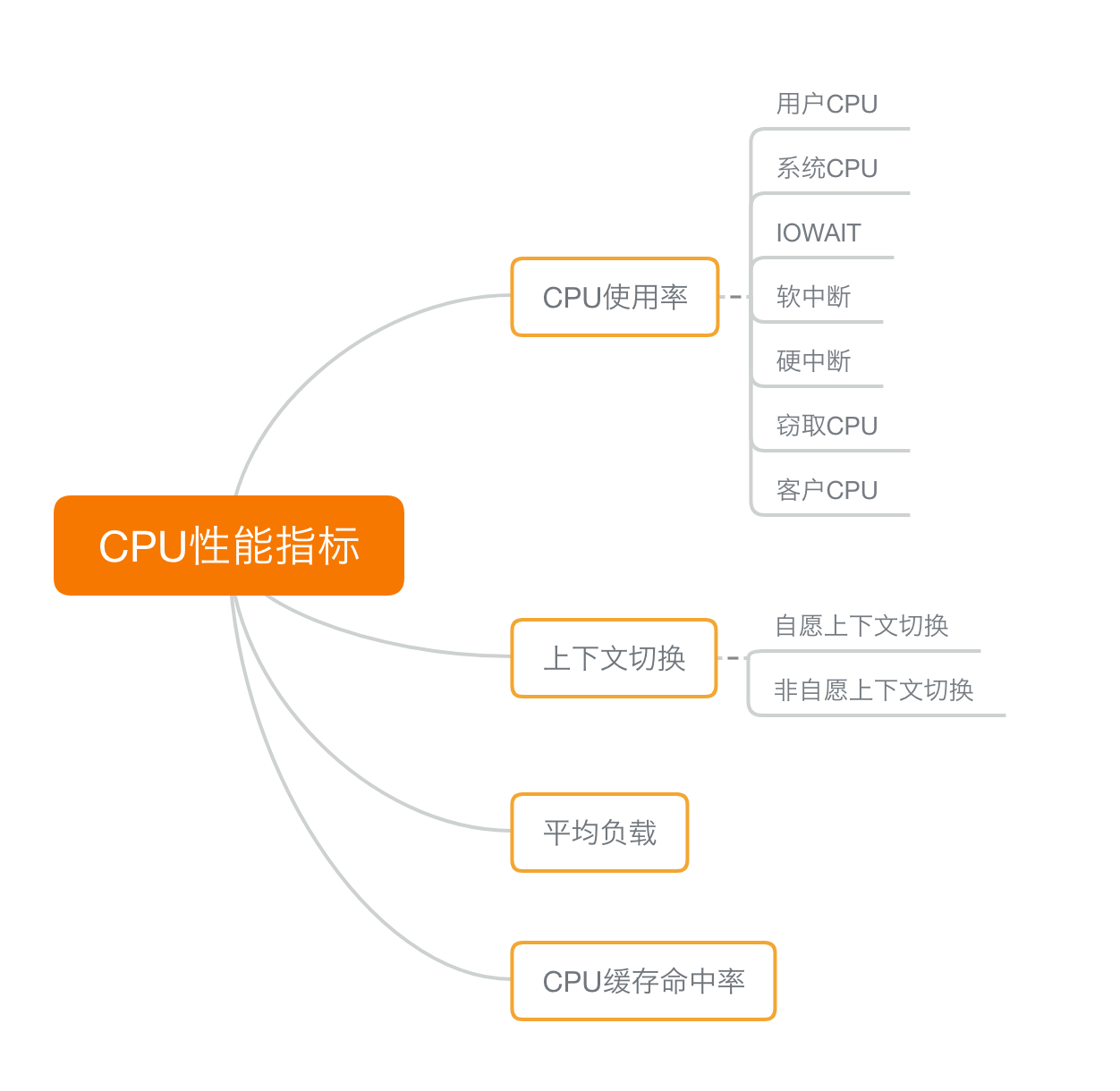
平均负载
概念
可运行状态和不可中断状态的平均进程数
- 可运行状态:即为正在运行或者等待被运行的进程(进程状态为R)
- 不可中断状态:正在处于关键流程的进程(进程状态为D),常用的是等待硬件I/O响应,例如为了保证数据一致性,在写入数据时候,磁盘没用回应之前,该进程是不可被中断,这是系统对进程和硬件设备的一种保护措施
平均负载可以简单理解为单位时间内活跃的进程数,如果该值大于cpu核数的话就是过载了。一般情况下平均负载超过cpu核数的70%了,就应该去查看原因。
如何查看
两种方法查看:
1 | root@ubuntu:/home/drecik# uptime |
load average后面的值分别代表了最近1分钟,3分钟,5分钟的平均负载值
或者使用top命令,第一行的最后数据就是平均负载
1 | root@ubuntu:/home/drecik# top |
CPU上下文切换
概念
Linux是一个多任务操作系统,可以支持远大于cpu数量的任务同时运行。这里的同时指的是并发,Linux在很短的时间内把CPU轮流分配给它们去执行。CPU上下文切换是保证Linux系统该功能正常工作的核心之一,过多的上下文切换会把CPU时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,从而缩短进程真正的执行时间,导致系统整体的性能大幅下降。
进程上下文
为了能够支持CPU轮流给不同进程去执行,所以在该进程让出CPU之前,我们需要保存该进程正在运行的现场(CPU中该进程的各个寄存器值,程序当前执行的位置,虚拟内存等信息)。这样下次轮到该进程再次执行的时候能够恢复当时的运行现场,进程就能够继续往下执行。保存和恢复的现场就是进程的上下文。
内核上下文切换
Linux按照特权等级,把运行空间分为内核空间和用户空间。每个运行空间都有独立的堆栈。当进程处于用户态的时候调用系统调用就会进入到内核态。这个时候需要保存该进程用户空间的当前的现场(寄存器,程序当前位置等),然后恢复内核空间的现场,进入到内核空间执行内核代码。系统调用完毕之后,保存内核空间现场,恢复用户空间现场。继续执行用户空间代码。所以一次系统调用会发生两次CPU上下文切换。但是因为这还是属于同一个进程中,保存和恢复的现场会比进程切换的小,所以开销没有进程切换的大。
线程上下文切换
线程是CPU调度和运行的基本单位,而进程是资源申请的基本单位。当一个进程拥有多个线程的时候,多个线程将共享进程的很多资源(内存空间,硬件资源等)。所以如果发生线程上下文切换的时候,切换的内容会比进程切换少很多。
中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,相应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
发生CPU上下文切换的场景
- CPU时间片跑满,被动释放CPU给另外个进程
- 系统资源不足(内存/硬盘),挂起进程,等待资源满足
- 硬件中断,挂起进程,去执行内核相关中断代码
- 主动sleep,主动释放CPU给另外个进程
- 更高优先级进程运行,保证高优先级进程优先执行
- 调用内核函数
如何查看
工具:
- sysstat:包含了linux常用的多核性能分析工具,用来监控核分析系统的性能
查看系统总体情况
1 | drecik@ubuntu:~$ vmstat 5 |
- 5表示5秒输出一组数据
- cs(context switch):每秒上下文切换次数
- in(interrupt):每秒中断次数
- r(Running or Runnable:就绪队列长度,也就是正在运行或者正在等待运行的进程数
- b(Blocked):处于不可中断睡眠状态的进程数
查看进程的情况
1 | drecik@ubuntu:~$ pidstat -w 5 |
cswch:每秒自愿上下文切换次数(获取不到资源,或者主动sleep)
nvcswch:每秒非自愿上下文切换次数(时间片跑满,被系统切换),大量进程抢占的时候会导致该值偏高
pidstat还有另外两个参数-u -t,-u表示输出CPU指标,-t表示显示现场的上下文切换情况
如何判断异常
这些切换列取值多少该合适:取决于cpu性能,但是这些数值应该稳定才行,如果某一个数值出现增长,那可能就导致性能问题:
- 如果是cswch增长,说明等待资源的进程变多,可能是I/O等其他问题
- 如果是nvcswch增长,说明CPU紧张了
- 如果是in增长了,说明CPU被中断处理程序占用,需要进一步分析什么中断导致,例如查看
/proc/interrupts文件查看是什么中断导致
CPU使用率
概念
CPU使用率是一个更常用更直观的一个指标来描述机器或者某个进程的负载情况。了解CPU使用率之前需要知道CPU把时间划分为很短的时间片,在通过调度器将这些时间片分配给任务使用。Linux通过节拍率(HZ)来表示这些时间片的长度。并使用全局变量Jiffies来记录开机以来的节拍数。节拍率是内核选项,可以通过命令grep 'CONFIG_HZ=' /boot/config-$(uname -r)查询查看。该值在不同操作系统可能不一样。
Linux提供另外一个用户空间的接拍率(USER_HZ),该值固定为100。
查看CPU数据
1 | drecik@ubuntu:~$ cat /proc/stat | grep ^cpu |
通过查看虚拟文件/proc/stat查看,第一行cpu是总的CPU使用情况,第二行开始是每个CPU每个核的使用情况。每一列的数值代表该cpu在这种模式下的(USER_HZ)次数,每一列的意思:
- user(缩写为us):用户态的CPU时间,不包括nice,但包括guest时间。如果该值过高,则说明用户进程负载比较严重,需要重点查看用户进程的性能问题
- nice(缩写为ni):处于低优先级用户态的CPU时间
- system(缩写为sys):处于内核态的CPU时间。如果该值过高,说明占用了过多的内核时间,需要重点排查内核线程或者系统调用相关的性能问题。
- idle(缩写为id):空闲时间。不包括iowait时间。
- iowait(缩写为wa):等待I/O的时间。该值可能不太准确。如果该值过高,说明等待I/O时间过长,需要重点排查存储系统是否出问题
- irq(缩写为hi):处理中断的时间。
- softirq(缩写为si):处理软中断的时间。如果该值与irq值过高,说明系统中断处理程序占用了较多CPU,需要重点排查内核的终端服务程序
- steal(缩写为st):当处于虚拟机环境时,cpu被其他虚拟系统占用的时间
- guest:运行虚拟机的CPU时间(为什么是0)
- guest_nice(缩写为gnice):以低优先级运行虚拟机的时间
上面数据记录的是开机到现在CPU处于这些状态的所有USER_HZ次数。所以如果要计算从开机到现在的CPU使用率可以通过公式1-空间时间/总时间得到。如果要得到要得到某一个时间间隔的CPU使用率,则可以在这个时间间隔开始时候查看该文件记录各个数据,时间间隔结束的时候再记录一次,通过公式**平均CPU使用率=1-(空闲时间2-空间时间1)/(总时间2-总时间1)**得到。
通过查看/proc/[pid]/stat可以得到某个进程的CPU使用情况。但这个数据列会更多,可以通过man proc查看详细数据
查看CPU使用率
top命令
top默认使用3秒的采集间隔,显示了系统总体的CPU和内存使用情况,以及各个进程的资源使用情况。使用很简单,直接输入top即可:
1 | drecik@ubuntu:~$ top |
- 第三列%CPU就是当前系统的CPU使用率情况(后面跟着是每种情况的CPU使用率),按下1就可以查看每个核的CPU使用率
- 空行之后是每个进程的资源使用情况:每个进程有一个%CPU列,表示进程的使用率,它是用户态和内核态的CPU使用率总和,包括进程在用户空间使用CPU、通过系统调用执行内核空间CPU,就绪队列等待运行的CPU,以及虚拟机环境下运行虚拟机的CPU。
pidstat
top命令CPU没有区别各种情况的使用率,可以使用pidstat来显示进程更细分的CPU使用情况
1 | # 1秒为间隔,输出5组数组,最后还有个平均值 |
- %usr:用户空间CPU使用率
- %system:系统空间CPU使用率
- %guest:虚拟机环境,运行虚拟机CPU使用率
- %wait:等待CPU使用率
- %CPU:总的CPU使用率
排查CPU问题一般思路
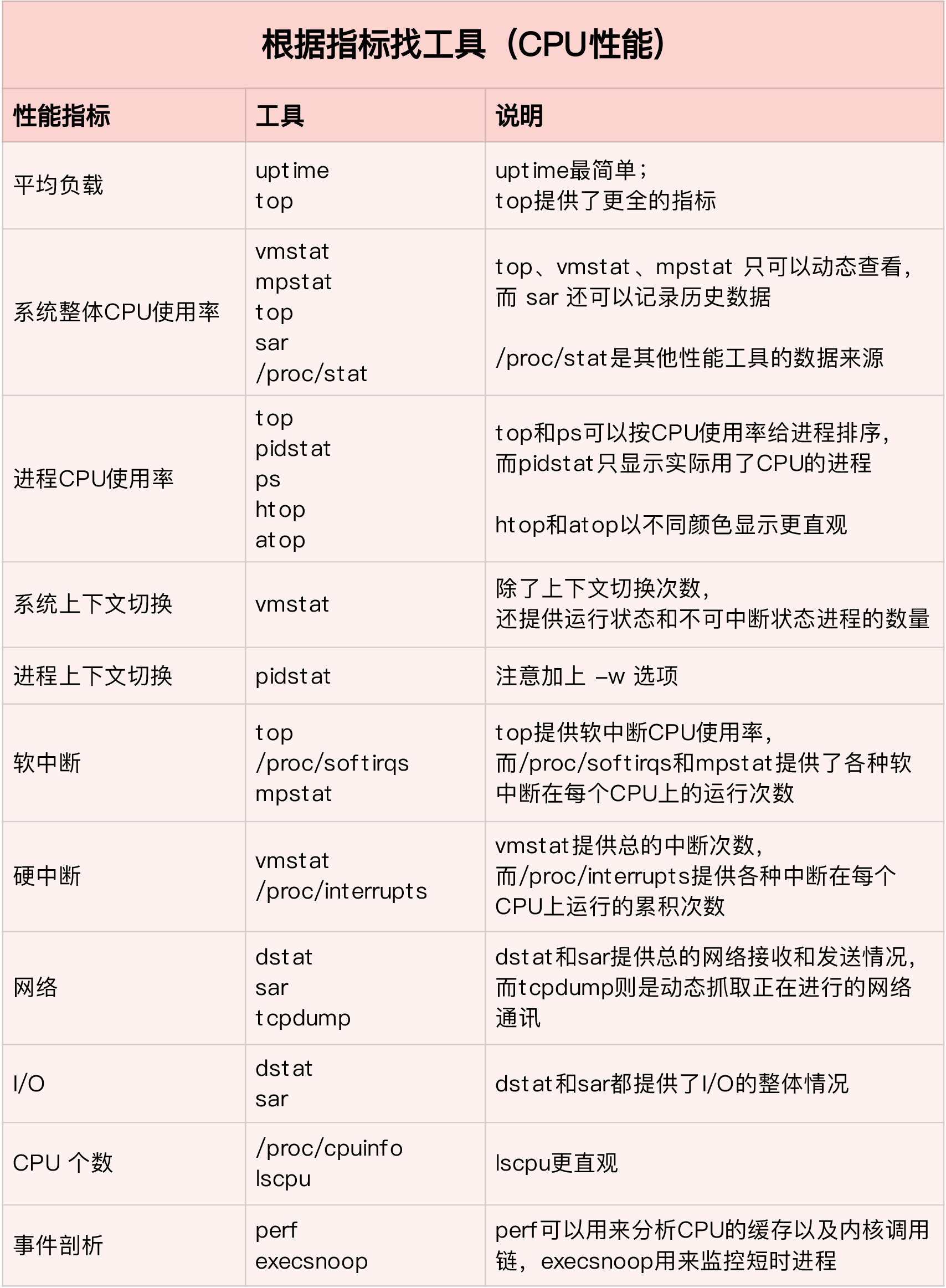
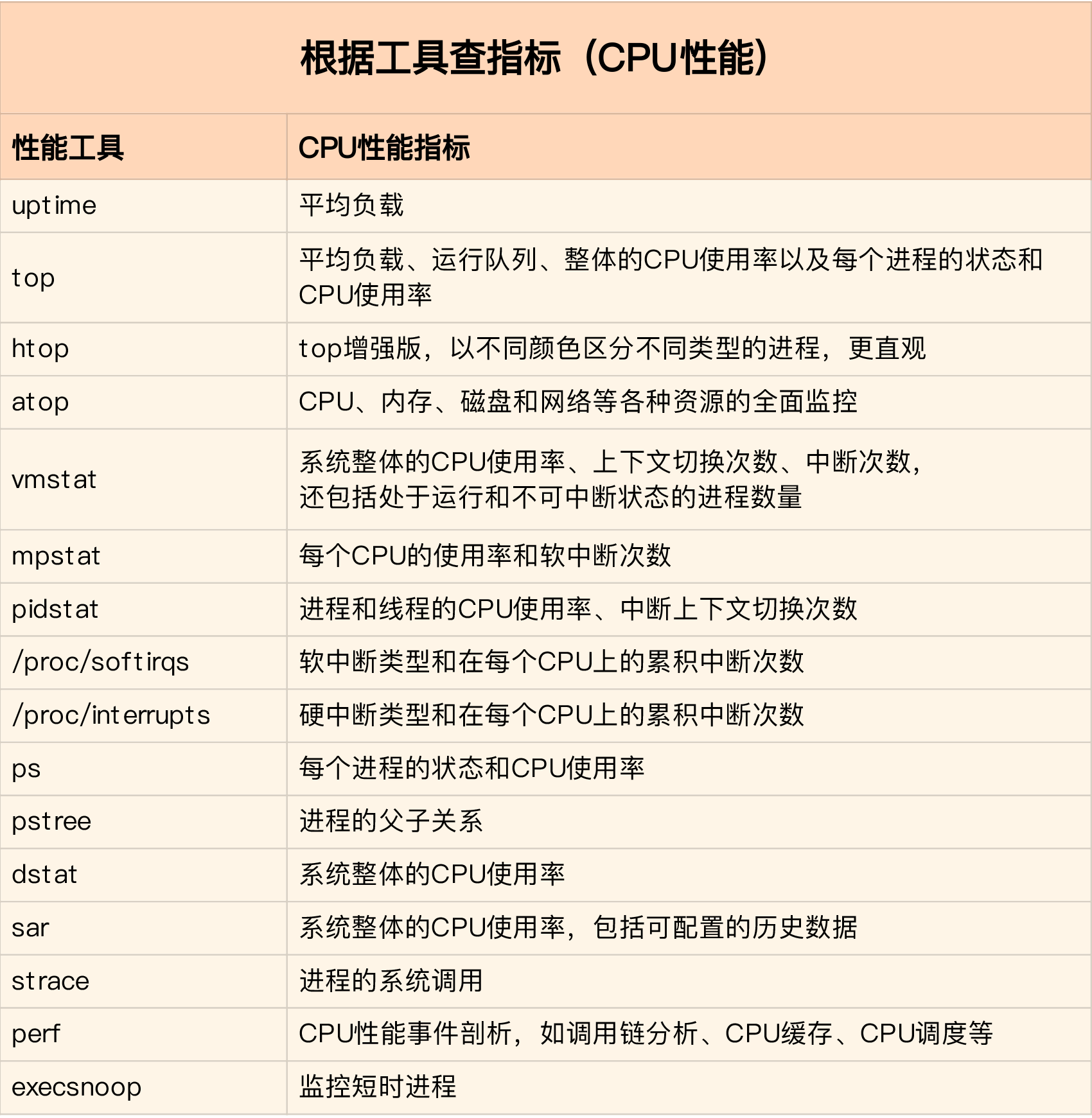
常用的CPU性能指标
速查图:CPU性能指标 -> 工具
速查图:工具 -> CPU性能指标
CPU性能问题查找思路图
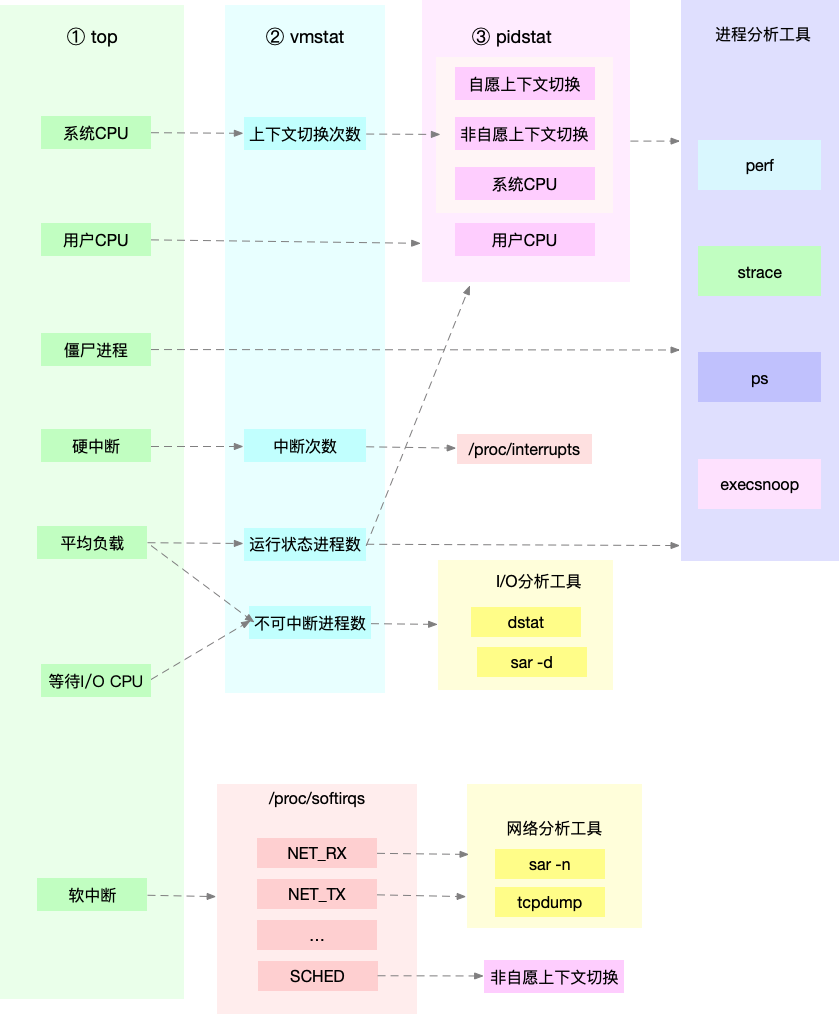
其他可能遇到比较棘手的问题
进程里调用了其他进程,并且该类进程执行时间较短,如果该操作不断执行导致的CPU升高,top和pidstat等工具都不容易发现。可能的一种情况就是某个进程一直在崩溃重启,而在启动的过程中会初始化资源导致CPU过高。这种情况下可以尝试下面的排查方式:
- 使用pstree或者execsnoop找到他们的父进程,并分析相关代码的原因
- 使用perf工具采样分析当前CPU占用情况
CPU性能优化思路
性能优化前需要考虑的问题
- 如何判断优化后是否有效,及提升性能提升多少?
- 性能问题不是独立的,在有多个性能问题同时发生的时候,应该首先优化哪个?
- 提升性能的方法不是唯一的,当有多种方法选择的时候,该选择哪个?
这三个问题在优化性能的时候要考虑清楚,特别是第一个问题,需要考虑优化前后,该使用哪个指标来进行对比。同时也要考虑多维度的指标,例如web应用情况下,可以考虑两个维度:
- 应用程序维度,我们可以通过吞吐量和请求延迟来评估应用程序性能
- 系统资源维度,我们可以通过CPU使用率来评估系统CPU使用情况
优化思路
应用程序优化
- 编译器优化
- 算法优化
- 异步处理
- 多线程替代多线程
- 善用缓存
系统优化
- CPU绑定
- CPU独占
- 优先级调整
- 为进程设置资源限制
- NUMA(Non-Uniform Memory Access)优化
- 中断负载均衡
避免过早优化
性能优化应该避免过早进行,因为:
- 性能优化往往会带来复杂性的提升,降低可维护性
- 需求不断变动,优化完了需求很有可能就改了
所以性能优化最好是一个逐步完善的过程,不要追求一步到位。
个人性能分析过程的总结
在分析进程CPU使用率占用过高的一个神器是perf,通过极小的性能开销就可以分析进程当前哪些函数开销过高,从而缩小进程性能瓶颈的排查范围。如果可以的话线上也部署相应的环境,方便查找出现的性能问题